前言
最近学习了黄建宏大佬的《redis设计与实现》,真心觉得redis非常非常强(建宏大佬也强),但是我觉得书本的阅读始终是入门, 真正要深入redis的思想和原理,还是要去看一看源码。
于是我就在redis源码下载地址上下载了redis7.0.4版本的源码;结合网上一些大佬的博客,开始阅读redis。
redis源码阅读起来并不是一件简单的事情,并且也想着不是阅读一次就算了,我决定开个blog记录一下阅读的内容。
如果您能看到我的blog并且感到有帮助,我倍感荣幸
ADList
ADList相关的源码在adlist.h和adlist.c文件中
ADList的源码相对于SDS来说非常好理解,如果在阅读之前有数据结构的基础(特别是双向链表),那阅读起来基本是无压力。
数据结构
adlist的主要结构体:
typedef struct listNode {
struct listNode *prev; // 指向上一个节点
struct listNode *next; // 指向下一个节点
void *value;
} listNode;
// 迭代器
typedef struct listIter {
listNode *next;
int direction; // 迭代器的方向
} listIter;
// 双向链表
typedef struct list {
listNode *head; // 头指针
listNode *tail; // 尾指针
void *(*dup)(void *ptr); // 自定义节点值的复制函数
void (*free)(void *ptr); // 自定义节点值的释放函数
int (*match)(void *ptr, void *key); // 用来比较两个值是否相等
unsigned long len; // 用来记录链表长度, 保证O(1) 返回链表长度
} list;上面的结构非常的简单, 需要注意的是:
void *(*dup)(void *ptr);是自定义节点值的复制函数,如果不定义,默认策略的复制操作会让原链表和新链表共享同一个数据域int (*match)(void *ptr, void *key);search操作的时候比较两个value是否相等,默认策略是比较两个指针的值。len是用来纪录链表长度,但是要注意记录长度不包括头尾指针- 迭代器中的
direction有两个值,分别是:
#define AL_START_HEAD 0 // 从头遍历
#define AL_START_TAIL 1 // 从尾遍历下面来看看图示:
可以看到, 左边的就是list结构体, 其中list.head链接着lsitNode, 实际存储数据的是listNode,每一个listNode都有头尾指针, 链接着下一个(或上一个)listNode, 最后一个listNode的next指针连接着list的tail节点。
链表结构的优势在于插入和删除的便利 ,因为链表的数据节点是分配在不同的内存区域的,并不连续,只是根据上一个节点保存下一个节点的顺序来索引而己,无需移动元素。
链表的创建函数
list *listCreate(void)
{
struct list *list;
// 这里是出错的情况,当链表申请内存出错时, 返回NULL
if ((list = zmalloc(sizeof(*list))) == NULL)
return NULL;
list->head = list->tail = NULL;
list->len = 0;
list->dup = NULL;
list->free = NULL;
list->match = NULL;
return list;
}说实话,没什么特别的,作者特别备注了一下创建的list可以使用listRelease()释放,但在释放链表之间必须保证每个节点都有释放。
链表的清空
链表的清空指的是删除链表中所有的元素,但链表本身还是存在的,换句话说,删除所有的listnode并free,但是list本身没有被删除。
/* Remove all the elements from the list without destroying the list itself. */
void listEmpty(list *list)
{
unsigned long len;
listNode *current, *next;
current = list->head;
len = list->len;
while(len--) {
next = current->next;
// 如果有自定义的free函数就使用自定义的free
if (list->free) list->free(current->value);
zfree(current);
current = next;
}
list->head = list->tail = NULL;
list->len = 0;
}链表的释放
这一步才是将整个链表删除, 这里其实也比较简单, 删除链表中所有的元素, 再删除链表
void listRelease(list *list)
{
listEmpty(list);
zfree(list);
}链表的插入
双向链表代表着链表头部和尾部都可以插入, 我们分别看看这两个插入函数
头插法
/* Add a new node to the list, to head, containing the specified 'value'
* pointer as value.
*
* On error, NULL is returned and no operation is performed (i.e. the
* list remains unaltered).
* On success the 'list' pointer you pass to the function is returned. */
list *listAddNodeHead(list *list, void *value)
{
listNode *node;
// 如果申请内存失败, 就返回空值
if ((node = zmalloc(sizeof(*node))) == NULL)
return NULL;
node->value = value;
if (list->len == 0) {
list->head = list->tail = node;
node->prev = node->next = NULL;
} else {
node->prev = NULL;
node->next = list->head;
list->head->prev = node;
list->head = node;
}
list->len++;
return list;
}步骤解析
new一个链表节点, 并把要插入的值赋给node->value- 如果链表中没有元素, 则让新节点的头指针和尾指针都指向
node,并且node的头尾指针都置为空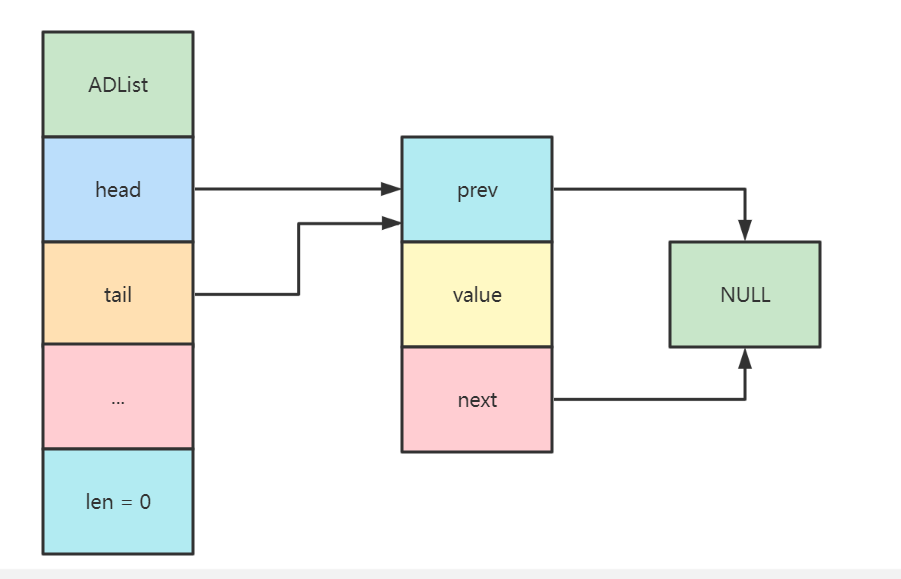
- 如果链表中有元素,那么因为是头插法,
node的上级是没有元素的,所以先让node的上级置空,然后再把新节点插入到头部,具体操作如下图: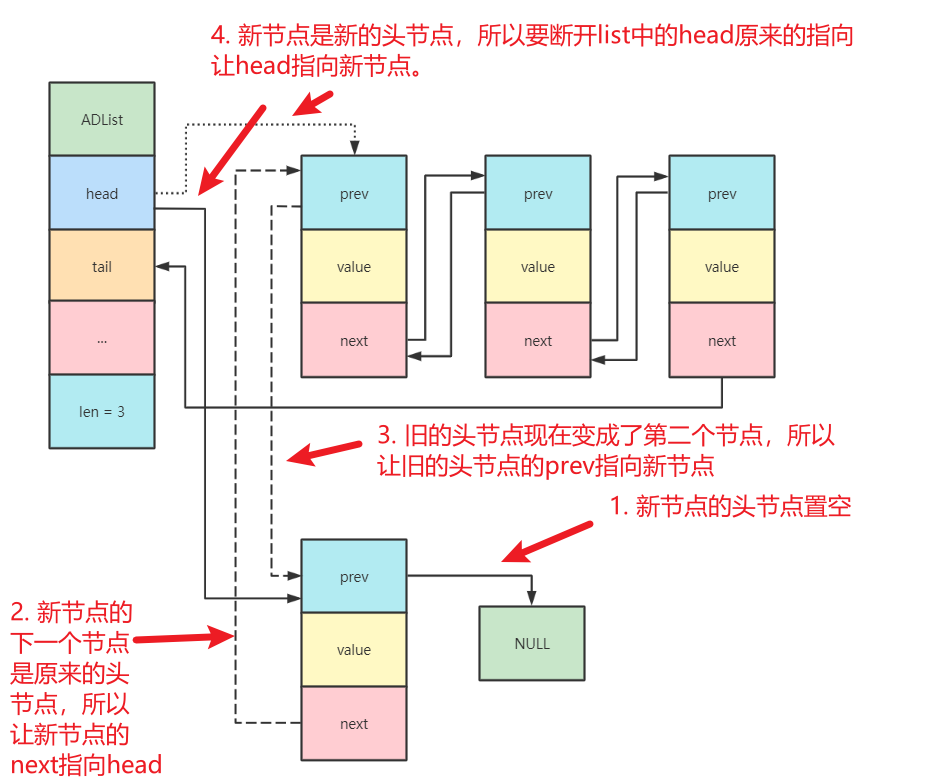
- 执行完成后,
len++,并返回链表
尾插法
/* Add a new node to the list, to tail, containing the specified 'value'
* pointer as value.
*
* On error, NULL is returned and no operation is performed (i.e. the
* list remains unaltered).
* On success the 'list' pointer you pass to the function is returned. */
list *listAddNodeTail(list *list, void *value)
{
listNode *node;
if ((node = zmalloc(sizeof(*node))) == NULL)
return NULL;
node->value = value;
if (list->len == 0) {
list->head = list->tail = node;
node->prev = node->next = NULL;
} else {
node->prev = list->tail;
node->next = NULL;
list->tail->next = node;
list->tail = node;
}
list->len++;
return list;
}尾插法也是差不多的意思,这里就不过多赘述。
指定元素的前/后插入
list *listInsertNode(list *list, listNode *old_node, void *value, int after) {
listNode *node;
if ((node = zmalloc(sizeof(*node))) == NULL)
return NULL;
node->value = value;
if (after) { //在指定节点后面插入
node->prev = old_node; //让新节点prev指向旧节点
node->next = old_node->next; //让新节点的next指向旧节点的next
if (list->tail == old_node) { // 这里的意思是如果指定的节点(old_node)是tail, 那就在这里让tail变成新的tail
// 其实很好理解, 就是在tail后面插了新节点, 那新节点就是新的tail
list->tail = node;
}
} else { //默认在指定节点前面插入
node->next = old_node;
node->prev = old_node->prev;
if (list->head == old_node) { // 这里同理, 如果在head前面插入一个元素, 那新节点就是新的head
list->head = node;
}
}
if (node->prev != NULL) {
//在指定节点后面插入时,更新旧节点的next指向新节点
node->prev->next = node;
}
if (node->next != NULL) {
//在指定节点前面插入时,更新旧节点的pre指向新节点
node->next->prev = node;
}
list->len++;
return list;
}指定位置插入元素, 代码还是很好理解的, 我就把解析放在注释里了,这样配合代码比较好读
链表的删除
/* Remove the specified node from the specified list.
* It's up to the caller to free the private value of the node.
*
* This function can't fail. */
void listDelNode(list *list, listNode *node)
{
if (node->prev) // 判断要删除的节点前面还有没有节点
node->prev->next = node->next; // 如果有节点,就让上一个节点的next指针指向被删除节点的下一个
else
// 如果没有节点 那就让头节点指向被删除节点的下一个
list->head = node->next;
if (node->next) // 判断要删除的节点后面还有没有节点
node->next->prev = node->prev; // 如果有节点,就让下一个节点的prev指针指向被删除节点的上一个
else
// 如果没有节点 那就让尾节点指向被删除节点的上一个
list->tail = node->prev;
// 这里指如果有自定义的free方法, 就用自定义的free方法去释放节点值
if (list->free) list->free(node->value);
zfree(node);
list->len--;
}链表的遍历
list提供迭代器,可以实现顺序或逆序遍历
获取迭代器
listGetIterator获取一个list的迭代器,方向由direction指定。
/* Returns a list iterator 'iter'. After the initialization every
* call to listNext() will return the next element of the list.
*
* This function can't fail. */
listIter *listGetIterator(list *list, int direction)
{
listIter *iter;
if ((iter = zmalloc(sizeof(*iter))) == NULL) return NULL;
if (direction == AL_START_HEAD)
// 正序
iter->next = list->head;
else
// 逆序
iter->next = list->tail;
iter->direction = direction;
return iter;
}
/*
listGetIterator获取的迭代器需要调用listReleaseIterator释放
*/
void listReleaseIterator(listIter *iter) {
zfree(iter);
}迭代器遍历
listNext返回迭代器的当前值,并将其后移一位指向下一个值。
listNode *listNext(listIter *iter)
{
listNode *current = iter->next;
if (current != NULL) {
if (iter->direction == AL_START_HEAD)
// 正序
iter->next = current->next;
else
// 逆序
iter->next = current->prev;
}
return current;
}重置迭代器
遍历结束之后,如果需要重新遍历。可以重置迭代器,不用创新创建。重置时可以选择从头部还是尾部开始遍历。
/* Create an iterator in the list private iterator structure */
void listRewind(list *list, listIter *li) {
li->next = list->head;
li->direction = AL_START_HEAD;
}
void listRewindTail(list *list, listIter *li) {
li->next = list->tail;
li->direction = AL_START_TAIL;
}链表的复制
list *listDup(list *orig)
{
list *copy;
listIter iter;
listNode *node;
// 链表创建失败, 返回NULL
if ((copy = listCreate()) == NULL)
return NULL;
copy->dup = orig->dup;
copy->free = orig->free;
copy->match = orig->match;
// 重置迭代器指向头节点
listRewind(orig, &iter);
while((node = listNext(&iter)) != NULL) {
void *value;
if (copy->dup) {
// 如果自定义了dup,使用该函数复制值
value = copy->dup(node->value);
if (value == NULL) {
// 空间分配失败,清理,返回NULL
listRelease(copy);
return NULL;
}
} else {
value = node->value;
}
if (listAddNodeTail(copy, value) == NULL) {
// 空间分配失败,清理,退出
if (copy->free) copy->free(value);
listRelease(copy);
return NULL;
}
}
return copy;
}通俗易懂, 就是把旧的链表从头遍历一遍, 遍历的同时申请空间拼接到新链表上
链表中查找指定的key
遍历整个list查找指定的key
listNode *listSearchKey(list *list, void *key)
{
listIter iter;
listNode *node;
listRewind(list, &iter);
while((node = listNext(&iter)) != NULL) {
if (list->match) {
// 如果有自定义的match函数就用match函数去比较
if (list->match(node->value, key)) {
return node;
}
} else {
// 没有的话就直接比较
if (key == node->value) {
return node;
}
}
}
return NULL;
}要注意这里的key对应的是listnode里的值,因为这不是字典(dict)
其他操作
主要的链表操作在上面已经说完了, 现在就来看看list提供但是用的相对比较少的几个方法
返回指定索引处节点
listIndex返回指定索引处的节点,索引为负时从尾部计算。索引0表示第一个节点,1表示第二个节点,索引-1表示倒数第一个节点等等。
listNode *listIndex(list *list, long index) {
listNode *n;
if (index < 0) {
index = (-index)-1;
n = list->tail;
while(index-- && n) n = n->prev;
} else {
n = list->head;
while(index-- && n) n = n->next;
}
return n;
}将最后一个节点移到头部
void listRotateTailToHead(list *list) {
if (listLength(list) <= 1) return;
// 分离尾节点
listNode *tail = list->tail;
list->tail = tail->prev;
list->tail->next = NULL;
/* Move it as head */
list->head->prev = tail;
tail->prev = NULL;
tail->next = list->head;
list->head = tail;
}将第一个节点移到尾部
void listRotateHeadToTail(list *list) {
if (listLength(list) <= 1) return;
listNode *head = list->head;
// 分离头节点
list->head = head->next;
list->head->prev = NULL;
/* Move it as tail */
list->tail->next = head;
head->next = NULL;
head->prev = list->tail;
list->tail = head;
}合并链表
void listJoin(list *l, list *o) {
if (o->len == 0) return;
// 后一个链表的头节点的prev指针指向前一个链表的尾指针
o->head->prev = l->tail;
if (l->tail)
// 如果前一个链表的尾指针有值, 就让尾指针的next指向后一个链表的头指针
l->tail->next = o->head;
else
// 链表没有尾指针说明链表为空, 所以让头指针直接指向后一个链表的头指针
l->head = o->head;
// 两个链表合并了, 所以让前一个链表的尾指针指向后一个链表的尾指针
l->tail = o->tail;
l->len += o->len;
// 这里其实就是废弃掉后一个指针了
o->head = o->tail = NULL;
o->len = 0;
}总结一波
- 链表的内容相对于sds可简单太多了, 基本上就是数据结构一把梭, 能懂双向链表的同学估计稍微想想就明白了
- 比较有意思的几个点就是
list的迭代器, 因为是双向链表, 所以迭代器可以选择从头迭代还是从尾迭代, 相比于直接迭代, 在代码实现上还是很方便的 - 有空的小伙伴可以去试试实现一个双向链表, 实现完后就会发现你居然实现了redis里的list!(逃

4 条评论
幽默外壳包裹严肃内核,寓教于乐。
想想你的文章写的特别好www.jiwenlaw.com
不错不错,我喜欢看
看的我热血沸腾啊https://www.jiwenlaw.com/