前言
最近学习了黄建宏大佬的《redis设计与实现》,真心觉得redis非常非常强(建宏大佬也强),但是我觉得书本的阅读始终是入门, 真正要深入redis的思想和原理,还是要去看一看源码。
于是我就在redis源码下载地址上下载了redis7.0.4版本的源码;结合网上一些大佬的博客,开始阅读redis。
redis源码阅读起来并不是一件简单的事情,并且也想着不是阅读一次就算了,我决定开个blog记录一下阅读的内容。
如果您能看到我的blog并且感到有帮助,我倍感荣幸
SDS
SDS相关的源码在sds.h和sds.c文件中
redis没有直接使用c语言的字符串,而是自己定义了一个字符串数据结构:SDS(simple dynamic string)作为默认的字符串。我们设置的所有键值基本都是SDS。
为什么redi 要自己定义一个字符串数据结构
在《Redis 设计与实现》 中有提到
| 差别 | SDS | C语言内置字符串 |
|---|---|---|
| 获取字符串长度的时间复杂度 | O(1) | O(n) |
| 字符串函数是否会造成缓冲区溢出 | 否 | 是 |
| 每次修改字符串需要重新分配内存 | 否 | 是 |
| 二进制安全 | 是,可以保存文本,以及其他二进制 (图片等) 数据 | 否,只能存储文本 |
总结
- SDS是动态长度, 且在内存分配中存在冗余空间(后面代码分析中可见), 冗余空间能减少字符串在扩容、缩容等操作时对内存空间的操作,以提高性能
- SDS中有专门的元素用于记录长度, 所以无需遍历字符串获取长度
- 二进制安全
源码分析
1. SDS的定义
typedef char *sds; sds的定义是用于操作sdshdr结构
2. sdshdr结构体
之前的SDS结构体
sdshdr在redis3.2版本前后差异比较大,对比来说,3.2之前的sdshdr比较通俗易懂, 3.2之后的sdshdr稍微复杂。
struct sdshdr {
unsigned int len; // 记录已保存的字符长度
unsigned int free; // 记录剩余空间(字节长度)
char buf[]; // 字节数组, 用于保存字符数据
};
上面是在redis 3.2 之前的sds结构体
- 每个
sdshdr都是一个sds的值 len代表字符串的长度,如果len长度为6,就代表着sds保留了长度为6字节的字符串buf属性是一个char类型的数组,数组的前五个字节分别保存了'a'、'b'、'c'、'd'、'e'、'f'六个字符,而最后一个字节则保存了空字符'\0'因为我喜欢用新不用旧,就不再去探究原版代码了,见谅
现在的SDS结构体
3.2之后, sdshdr结构体变得更复杂了一些, 会根据字符串的长度划分不同的数据结构sdshdr5,sdshdr8,sdshdr16,sdshdr32,sdshdr64
根据注释可知,sdshdr5在实际代码中并没有被使用
/* Note: sdshdr5 is never used, we just access the flags byte directly.
* However is here to document the layout of type 5 SDS strings. */
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};- 除了sdshdr5的结构稍显不一致,其余基本一致
len表示SDS已使用的长度,与3.2版本之前一致(不包含‘\0’)alloc表示SDS的最大容量,即 buf 真实可用于存储字符串的空间(buf的真实分配大小-头尾空间),略小于buf字节数组的长度- 剩余空间
free = alloc-len flags表示字符串类型,占用1个字节,低3位表示header的类型buf是柔性数组(flexible array member)一些C语言的概念
packed或者attribute__((packed))关键字的作用就是用来打包数据的时候以 1 来对齐,比如说用来修饰结构体或者联合体的时候,那么这些成员之间就没有间隙了。如果没有加,那么这样结构体或者联合体就会以他的自然对齐方式来对齐。比如某CPU架构的编译器默认对齐方式是4, int的size也是4,char的 size 是1,那么类似typedef __packed struck test_s { char a; int b; } test_t;这样定义结构体的size就是8个字节(4字节对齐的情况下)。如果加上packed, size 就会变成5个字节,中间是没有间隙的。
我们再来看看对齐后SDS_TYPE_8、SDS_TYPE_16、SDS_TYPE_32、SDS_TYPE_64 的内存布局是怎样的: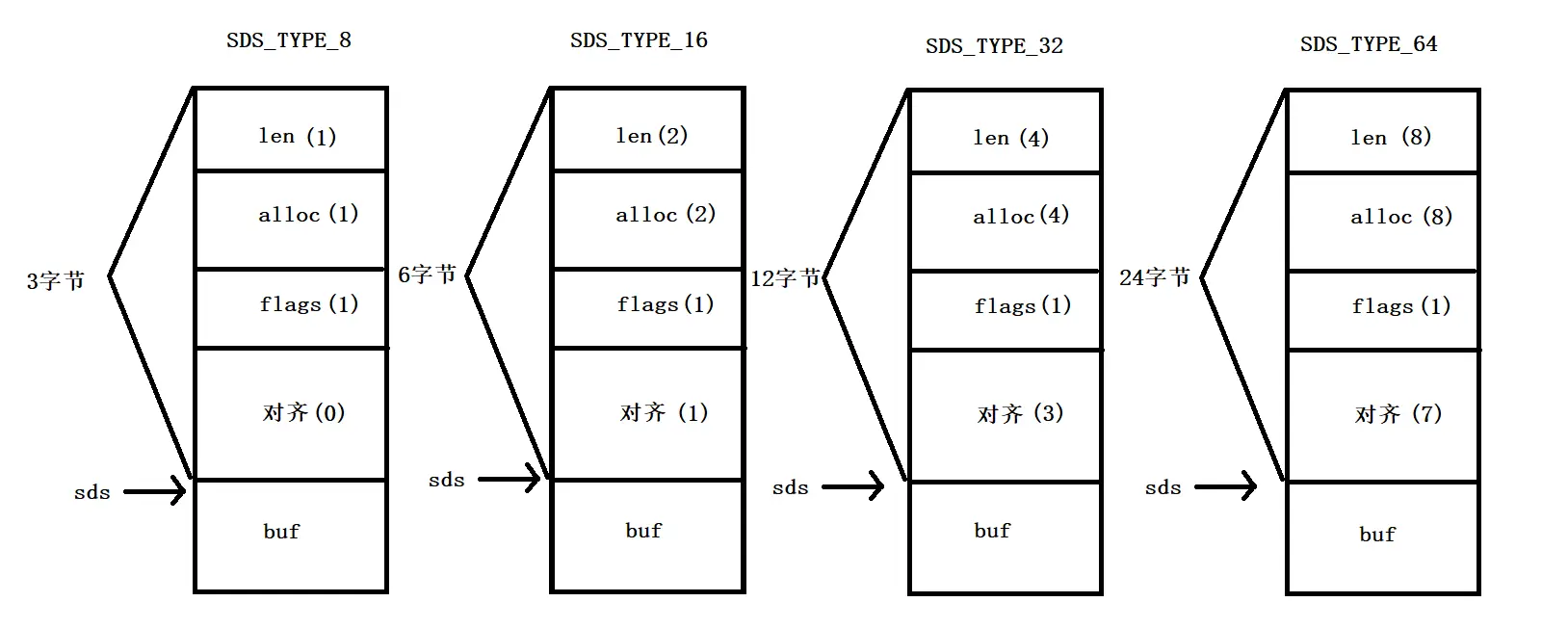
可以看到不同类型的sdshdr对齐的字节数不同,这就让(char*)buf - 1无法让每种 sdshdr都定位到flags的地址,如果想通过buf定位到flags的地址,需要进行类型判断,并且不同的系统可能有不同的对齐方式。
这个很重要, 因为redis中不是直接对sdshdr进行操作,参数都是sds,而sds就是结构体中的buf,所以在指针寻址的时候,就可以通过s[-1]这种魔法操作来找到对应的flags(因为在sdshdr的内存分布中s[-1]就是flags变量),从而通过flags来得知字符串的类型。
结构体中的数据类型
flags表示该字符串的类型(sdshdr5,sdshdr8,sdshdr16,sdshdr32,sdshdr64),是由flags的第三位表示的。其中的源码如下:
#define SDS_TYPE_5 0
#define SDS_TYPE_8 1
#define SDS_TYPE_16 2
#define SDS_TYPE_32 3
#define SDS_TYPE_64 4
#define SDS_TYPE_MASK 7从源码可以看出,SDS_TYPE只占用了0,1,2,3,4五个数字,正好占用三位。当判断类型时,就可以使用flag & SDS_TYPE_MASK来获取类型
获取长度
static inline size_t sdslen(const sds s) {
// 上面提到s[-1]可以直接获得flags
unsigned char flags = s[-1];
switch(flags&SDS_TYPE_MASK) {
case SDS_TYPE_5:
// 获取 SDS_TYPE_BITS = 3
return SDS_TYPE_5_LEN(flags);
case SDS_TYPE_8:
// 通过 SDS_HDR 获得结构体首地址
// 通过 len 获得对于大小
return SDS_HDR(8,s)->len;
case SDS_TYPE_16:
return SDS_HDR(16,s)->len;
case SDS_TYPE_32:
return SDS_HDR(32,s)->len;
case SDS_TYPE_64:
return SDS_HDR(64,s)->len;
}
return 0;
}从这两部分可以看出,sds的长度是通过SDS_HDR和SDS_TYPE_5_LEN两个宏定义得到的,让我们来看看这两个宏定义部分:
#define SDS_TYPE_BITS 3
#define SDS_HDR_VAR(T,s) struct sdshdr##T *sh = (void*)((s)-(sizeof(struct sdshdr##T)));
#define SDS_HDR(T,s) ((struct sdshdr##T *)((s)-(sizeof(struct sdshdr##T))))
#define SDS_TYPE_5_LEN(f) ((f)>>SDS_TYPE_BITS)其中连接符##用来将两个token连接为一个token,所以当编译器完成替换后为:
SDS_HDR(8,s);
==
((struct sdshdr8 *)((s) - (sizeof(struct sdshdr8))))主要是SDS_HDR,通过上面代码可以看出,SDS_HDR函数是通过 结构的首地址=(sds的字节数组)-(对应结构体的size)获得对于sds的引用, 再通过->len获得长度, 真的是很强的思路
接下来再看看,sds是怎么样获取剩余长度的
//获取sds中的可用空间
static inline size_t sdsavail(const sds s) {
unsigned char flags = s[-1];
switch(flags&SDS_TYPE_MASK) {
case SDS_TYPE_5: {
return 0;
}
case SDS_TYPE_8: {
SDS_HDR_VAR(8,s);
return sh->alloc - sh->len;
}
case SDS_TYPE_16: {
SDS_HDR_VAR(16,s);
return sh->alloc - sh->len;
}
case SDS_TYPE_32: {
SDS_HDR_VAR(32,s);
return sh->alloc - sh->len;
}
case SDS_TYPE_64: {
SDS_HDR_VAR(64,s);
return sh->alloc - sh->len;
}
}
return 0;
}其中使用的SDS_HDR_VAR(T,s)宏定义
#define SDS_HDR_VAR(T,s) struct sdshdr##T *sh = (void*)((s)-(sizeof(struct sdshdr##T)));翻译成代码就是
SDS_HDR_VAR(8,s);
==
struct sdshdr8 *sh = (void*)((s)-(sizeof(struct sdshdr8)));接着就可以直接使用*sh指针访问alloc和len属性。
sdshdr8在取消内存对齐后的结构体定义size是3个字节, uint8_t len, uint8_t alloc, flags 各占用1个字节,buf是柔性数组,初始值为0,不占用空间
SDS的创建
实际使用时,调用sdsnewlen生成新的sdshdr,根据init指针和initlen参数来初始化sds的内容, 代码如下
sds sdsnew(const char *init) {
size_t initlen = (init == NULL) ? 0 : strlen(init);
return sdsnewlen(init, initlen);
}
sds sdsnewlen(const void *init, size_t initlen) {
return _sdsnewlen(init, initlen, 0);
}
// 具体实现
sds _sdsnewlen(const void *init, size_t initlen, int trymalloc) {
void *sh;
sds s;
// 根据initlen获取合适的字符串长度
char type = sdsReqType(initlen);
// 最低使用SDS_TYPE_8
if (type == SDS_TYPE_5 && initlen == 0) type = SDS_TYPE_8;
// 获取对应的结构体长度
int hdrlen = sdsHdrSize(type);
unsigned char *fp; /* flags pointer. */
size_t usable;
assert(initlen + hdrlen + 1 > initlen); /* Catch size_t overflow */
/*
这里的malloc 申请了 initlen + hdrlen + 1 的空间
s_malloc_usable是用了一个别名来表示zmalloc函数
它会给sds多增加一个字节的空间,由后面的s[initlen] = '\0'
目的是为了兼容C语言的字符串类型, 可以直接使用printf来输出sds,真的太强了
*/
sh = trymalloc?
s_trymalloc_usable(hdrlen+initlen+1, &usable) :
s_malloc_usable(hdrlen+initlen+1, &usable);
if (sh == NULL) return NULL;
// 如果init == "SDS_NOINIT",那么就把sds置为未知字符串;
// 如果init == NULL,那么就会把sds置为空字符串
if (init==SDS_NOINIT)
init = NULL;
else if (!init)
memset(sh, 0, hdrlen+initlen+1);
s = (char*)sh+hdrlen;sh
fp = ((unsigned char*)s)-1;
// 根据sds类型来初始化sds的内容
switch(type) {
case SDS_TYPE_5: {
*fp = type | (initlen << SDS_TYPE_BITS);
break;
}
case SDS_TYPE_8: {
SDS_HDR_VAR(8,s);
sh->len = initlen;
sh->alloc = initlen;
*fp = type;
break;
}
case SDS_TYPE_16: {
SDS_HDR_VAR(16,s);
sh->len = initlen;
sh->alloc = initlen;
*fp = type;
break;
}
case SDS_TYPE_32: {
SDS_HDR_VAR(32,s);
sh->len = initlen;
sh->alloc = initlen;
*fp = type;
break;
}
case SDS_TYPE_64: {
SDS_HDR_VAR(64,s);
sh->len = initlen;
sh->alloc = initlen;
*fp = type;
break;
}
}
// 在初始化完成后,将init的内容拷贝进sds对象中,但是init如果原来等于SDS_NOINIT,就会被置为NULL,整个字符串就会被设置为未知字符串
if (initlen && init)
memcpy(s, init, initlen);
s[initlen] = '\0';
return s;
}在动态字符串的所有操作中,大部分会进行对内存的扩大和释放,
所以接下来会介绍一下sds中扩容和释放内存的函数
SDS的扩容
/* Enlarge the free space at the end of the sds string more than needed,
* This is useful to avoid repeated re-allocations when repeatedly appending to the sds. */
sds sdsMakeRoomFor(sds s, size_t addlen) {
return _sdsMakeRoomFor(s, addlen, 1);
}
/* Unlike sdsMakeRoomFor(), this one just grows to the necessary size. */
sds sdsMakeRoomForNonGreedy(sds s, size_t addlen) {
return _sdsMakeRoomFor(s, addlen, 0);sdsMakeRoomFor和sdsMakeRoomForNonGreedy为s增加adlen个字节的长度,可以看到这两个函数都是调用了_sdsMakeRoomFor接口,只不过在参数传递上,第三个参数有所不同。增容时如果sds中的buf空间已经足够容纳添加addlen之后的长度,则什么都不做;如果空间不足,则需要增容。
第三个参数如果是1,则增容时会多开一些空间,以便未来的增容有空间可用; 如果是0,则只会开辟加上 addlen 之后的空间大小,不会多预留空间。
我们再来深挖一下_sdsMakeRoomFor:
sds _sdsMakeRoomFor(sds s, size_t addlen, int greedy) {
void *sh, *newsh;
size_t avail = sdsavail(s); // 返回s的可用空间
size_t len, newlen, reqlen;
char type, oldtype = s[-1] & SDS_TYPE_MASK;
int hdrlen;
size_t usable;
/* Return ASAP if there is enough space left. */
if (avail >= addlen) return s;
len = sdslen(s);
sh = (char*)s-sdsHdrSize(oldtype); // 获取当前sds指针
reqlen = newlen = (len+addlen);
assert(newlen > len); /* Catch size_t overflow */
if (greedy == 1) {
if (newlen < SDS_MAX_PREALLOC)
newlen *= 2; // 如果扩容后的字符串小于1M,就分配两倍的内存
else
newlen += SDS_MAX_PREALLOC; // 如果拼接后的字符串大于1M,就分配多分配1M的内存
}
type = sdsReqType(newlen); // 根据长度获取新字符串的类型
/* Don't use type 5: the user is appending to the string and type 5 is
* not able to remember empty space, so sdsMakeRoomFor() must be called
* at every appending operation. */
if (type == SDS_TYPE_5) type = SDS_TYPE_8;
hdrlen = sdsHdrSize(type);
assert(hdrlen + newlen + 1 > reqlen); /* Catch size_t overflow */
if (oldtype==type) {
// 如果类型没变, 就realloc
newsh = s_realloc_usable(sh, hdrlen+newlen+1, &usable);
if (newsh == NULL) return NULL;
s = (char*)newsh+hdrlen;
} else {
/* Since the header size changes, need to move the string forward,
* and can't use realloc */
// 如果类型变化, 就需要重新malloc
newsh = s_malloc_usable(hdrlen+newlen+1, &usable);
if (newsh == NULL) return NULL;
memcpy((char*)newsh+hdrlen, s, len+1); // 老内存copy到新内存
s_free(sh); // 释放老内存
s = (char*)newsh+hdrlen;
s[-1] = type;
sdssetlen(s, len);
}
usable = usable-hdrlen-1;
if (usable > sdsTypeMaxSize(type))
usable = sdsTypeMaxSize(type);
sdssetalloc(s, usable);
return s;
}在这里我们可以看到《Redis 设计与实现》提到的 sds 预留空间策略(greedy == 1)的两种情况:
- 当
newlen < SDS_MAX_PREALLOC时(SDS_MAX_PREALLOC 的定义:#define SDS_MAX_PREALLOC (1024*1024)),即当新长度小于1MB时,预留空间长度为2 * newlen - 当
newlen >= SDS_MAX_PREALLOC,预留空间长度为 1MB
增容后的 sds 可能长度超越原 sdshdr 的最大长度,此时就要为 sds 分配一个新的 sdshdr。
SDS的释放
我粗略地在源码里找了找,缩短sds字符串的有三个函数:sdsclear、sdstrim、sdsrange,他们都不会改变alloc的大小即不会释放任何内存。
举个trim的例子:
sds sdstrim(sds s, const char *cset) {
char *end, *sp, *ep;
size_t len;
sp = s;
ep = end = s+sdslen(s)-1;
// strchr()函数用于查找给定字符串中某一个特定字符
while(sp <= end && strchr(cset, *sp)) sp++;
while(ep > sp && strchr(cset, *ep)) ep--;
len = (ep-sp)+1;
if (s != sp) memmove(s, sp, len);
s[len] = '\0';
// 仅仅更新了len
sdssetlen(s,len);
return s;
}从代码可以看到,trim函数仅仅只是缩短了字符串长度,内存空间并没有被释放,甚至空闲的空间都没有被置空。由于SDS是通过len值标识字符串长度,因此SDS完全不需要受限于c语言字符串的那一套\0结尾的字符串形式。在后续需要拼接扩展时,这部分空间也能够再次被利用起来,降低了内存重新分配的概率。
这就是sds字符串内存管理的一种方式:惰性释放。额外调用sdsRemoveFreeSpace释放内存,这样就节省了每次sds缩减长度而导致的内存释放开销。
可能会有hxd问:这没真正释放空间,不会导致内存泄漏吗?
下面介绍一下sdsRemoveFreeSpace,先放源码:
sds sdsRemoveFreeSpace(sds s) {
void *sh, *newsh;
char type, oldtype = s[-1] & SDS_TYPE_MASK;
int hdrlen, oldhdrlen = sdsHdrSize(oldtype);
size_t len = sdslen(s);
size_t avail = sdsavail(s);
sh = (char*)s-oldhdrlen;
/* Return ASAP if there is no space left. */
if (avail == 0) return s;
/* Check what would be the minimum SDS header that is just good enough to
* fit this string. */
type = sdsReqType(len);
hdrlen = sdsHdrSize(type);
/* If the type is the same, or at least a large enough type is still
* required, we just realloc(), letting the allocator to do the copy
* only if really needed. Otherwise if the change is huge, we manually
* reallocate the string to use the different header type. */
//这之后的代码就跟sdsMakeRoomFor后面的代码差不多了,如果收缩之后会导致类型的变化, 那么会重新malloc, 如果空间足够大, 就realloc
if (oldtype==type || type > SDS_TYPE_8) {
newsh = s_realloc(sh, oldhdrlen+len+1);
if (newsh == NULL) return NULL;
s = (char*)newsh+oldhdrlen;
} else {
newsh = s_malloc(hdrlen+len+1);
if (newsh == NULL) return NULL;
memcpy((char*)newsh+hdrlen, s, len+1);
s_free(sh);
s = (char*)newsh+hdrlen;
s[-1] = type;
sdssetlen(s, len);
}
sdssetalloc(s, len);
return s;
}SDS也提供了真正的释放空间的方法,以供真正需要释放空闲内存时使用。额外调用sdsRemoveFreeSpace释放内存,这样就节省了每次sds缩减长度而导致的内存释放开销。sdsRemoveFreeSpace这个函数压缩内存,让alloc=len。如果type变小了,则另开一片内存复制,重新执行sds加长操作,如果type不变,则realloc。
总结一波
redis 3.2之后,针对不同长度的字符串引入了不同的SDS数据结构,并且强制内存对齐1,将内存对齐交给统一的内存分配函数,从而达到节省内存的目的- SDS的字符串长度通过
sds->len来控制,不受限于C语言字符串\0,可以存储二进制数据,并且将获取字符串长度的时间复杂度降到了O(1) - 内存对齐交给内存分配函数后, SDS的头和buf字节数组的内存是连续的,可以通过寻址方式
s[-1]获取SDS的指针以及flags值 SDS有一个内存预分配策略,用空间减少每次拼接的内存重分配可能性, 通过源码可以看到内存的预分配策略主要有两种:
- 拼接后的字符串长度不超过1M,分配两倍的内存
- 拼接后的字符串长度超过1M,多分配1M的内存
- SDS的缩短并不会真正释放掉对应空闲空间
- SDS分配内存都会多分配1个字节用来在buf的末尾追加一个
\0,在部分场景下可以和C语言字符串保证同样的行为甚至复用部分string.h的函数
总的来说, Redis的sds设计真的是非常巧妙,但由于篇幅原因,其他的一些细节或者操作函数这里就不做详解了,如果感兴趣可以自行刷一波源码。SDS相关的源码在sds.h和sds.c文件中
