什么是消息队列?
消息队列是在消息的传输过程中保存消息的容器,简单点理解就是传递消息的队列,具备先进先出的特点,一般用于异步、解耦、流量削锋等问题,实现高性能、高可用、高扩展的架构。一个消息队列可以被一个或多个消费者消费,一般包含以下成员:
- Producer: 消息生产者,负责产生消息推送到Broker
- Broker:消息处理中心,负责消息存储、确认、重试,一般其中会有多个Queue
- Consumer:消息消费者,负责从Broker中获取消息,并进行相应处理
为什么要使用消息队列?
MQ的应用场景很多,有应用解耦、异步处理、流量削峰、日志处理、消息通信、消息广播等
但核心场景就三个:
- 解耦:将消息写入消息队列,需要消息的时候自己从消息队列中订阅,从而原系统不需要做任何修改。
- 异步:将消息写入消息队列,非必要的业务逻辑以异步方式运行,加快响应速度。
- 削峰:原系统按照数据库能处理的并发量从消息队列中拉取消息,在生产中,短暂的高峰期积压是被允许的。
解耦
假设有以下场景,用户向订单系统进行请求下单,订单系统中的逻辑调用为在下单成功之后还要调用积分系统、交易系统、短信系统,而其中短信系统调用失败了。但因为整个流程没有解耦,导致整个流程回滚且反馈给用户下单失败。

而引入MQ后,整个流程就解耦很多了,用户调用订单系统下单,订单系统在处理完订单相关事宜后发送消息到消息队列,下游系统再根据topic、tag等内容进行消息的消费,积分系统、交易系统、短信系统的成功与否不影响订单系统的流程,订单系统可以直接反馈下单成功的信息。

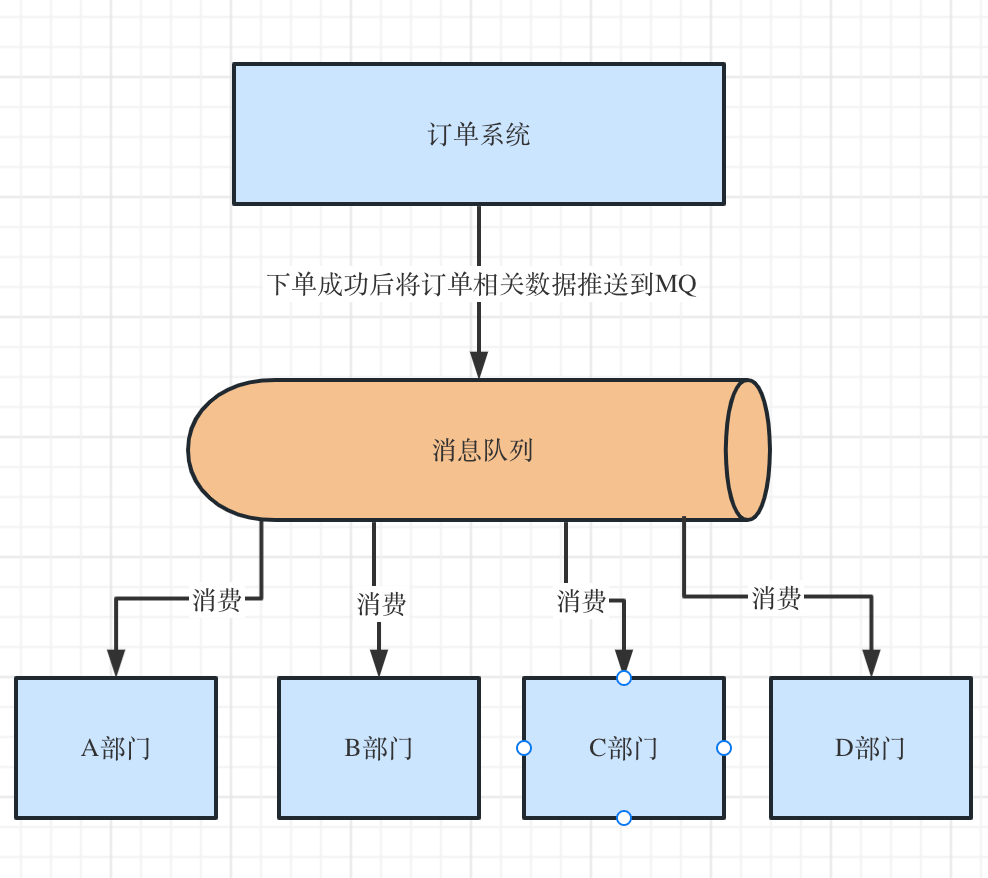
而如果再进一步,订单相关是公司的其中一个业务部门,此时有场景是用户下单后需要推送到大数据等部门做一些统计分析类的工作,如果此时有以下场景
1. A部门需要在订单数据的基础上增加用户相关信息数据X
2. B部门需要在订单数据的基础上增加用户历史购物数据Y
3. C部门只需要订单数据的部分数据
4. D部门需要订单数据,但需要进行封装如果不考虑MQ,那么这些操作都是需要修改代码才能实现,几个系统都耦合在一起了。
而引入MQ后,不需要在订单系统主动调用其他接口推送数据,只需要把数据推送到MQ中,哪些部门需要数据就自己去拉取就可以了。
异步
假设现在积分、交易、短信系统都是第三方服务,第三方服务可能会有宕机、执行缓慢的稳定性差的情况。如果没有MQ,当接口故障的时候要自己去编写重试逻辑(不关同步异步),还要考虑如果重试失败了是否要持久化下来在某个时间点通过定时任务重新推送,这一整个逻辑不仅仅影响功能复杂性,还影响性能。
如果有MQ,那么只需要把消息推送到MQ中,再从MQ中消费就可以了,如果接口不可用,直接给MQ返回消费失败,下次还可以重新拉取消息进行消费,不需要编写复杂的重试代码。

削峰
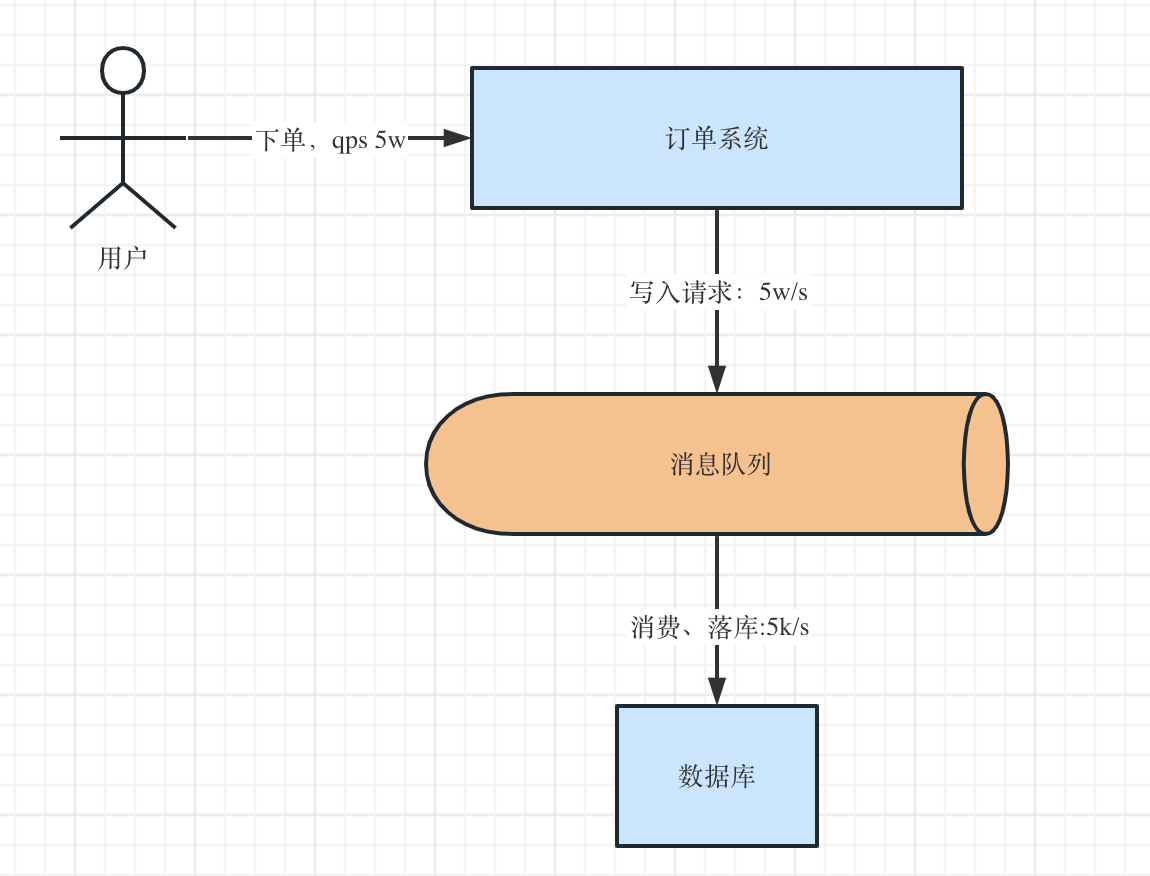
大部分业务中的性能瓶颈都会在数据库,假设数据库可以支撑5k qps,但是在某些场景中(比如双十一、618活动)中qps可能有3w甚至5w、10w,这时候巨大的压力会把数据库打爆。
而MQ扛几万的并发几乎没有任何问题,这时候我们就可以引入MQ,请求先写入到MQ中,再从MQ中慢慢消费落库。
此时写入MQ的QPS在3w,但消费MQ只有5k,积压的请求可以在后面慢慢消费,这样子可以扛住高于甚至远高于数据库可支撑的请求数量
消息队列有什么缺点?
引入新技术解决问题的同时会带来新的问题,只不过如果解决新问题比解决旧问题容易,那么引入新技术就是利大于弊的。
引入MQ也会带来问题,比如:
- 系统可用性降低:引入的外部依赖越多就越容易挂掉,比如上文提到,ABCD四个系统要采集订单系统的数据,老方法是订单系统完成后调用ABCD四个系统的接口,但是引入了MQ,如果MQ挂了,那ABCD也用不了了。
- 系统复杂度提高:本来架构技术栈很简单,但是引入了MQ,导致一些数据丢失、重复消费的问题,会使系统复杂度大大提高。
- 一致性问题:还是ABCD四个系统采集订单系统数据,订单系统完成后调用ABCD接口,调用B失败就不再调用BCD而直接回滚数据了,结果引入了MQ,订单系统在完成下单后推送消息到MQ就直接返回成功了,但实际上可能只有ABC成功了,D失败了,这时候要通过其他手段来保证数据一致性。
消息队列模型
- 点对点模式:多个生产者可以相同一个消息队列发送消息,一个消息只能被一个消费者消费,消费成功后这个消息会被移除,如果消费者处理消息失败了,那这条消息会重新被消费。

- 发布-订阅模式:单个消息可以被多个消费者并发获取、处理。多个生产者可以将多个消息写到同一个
topic中,被同一个消费者消费(topic中可以通过tag区分)

消息队列的选择
市面上常用的消息队列有Kafka、RocketMQ、RabbitMQ、ActiveMQ
下面根据特性和数据进行对比
| 特性 | RocketMQ | RabbitMQ | Kafka | ActiveMQ |
|---|---|---|---|---|
| 单机吞吐量 | 10万级,RocketMQ 也是可以支撑高吞吐的 MQ | 万级 | 10万级别,吞吐量高是kafka最大的优点 | 万级 |
| topic数量 | 千级,topic数量达到千级会有性能下降 | 百万级 | 百级 | 千级 |
| 消息顺序性 | 有序 | 有序 | 分区有序 | 有序 |
| 消息重复 | 至少一次,最多一次 | 至少一次 | 至少一次,最多一次 | 至少一次 |
| 时效性 | ms | 微秒级,RabbitMQ的一大优点 | ms | ms |
| 可用性 | 非常高,分布式架构 | 高,基于主从架构实现高可用性 | 非常高,分布式架构,一个数据多个副本,少数机器宕机,不会丢失数据,不会导致不可用 | 高,基于主从架构实现高可用性 |
| 消息可靠性 | 经过参数优化配置,理论上消息可以做到0丢失 | 有较低的概率丢失数据 | 经过参数优化配置,理论上消息可以做到0丢失 | 有较低的概率丢失数据 |
| 消息回溯 | 支持(按时间回溯) | 不支持 | 支持(按offset回溯) | 不支持 |
| 语言支持 | 支持Java、C++,但C++不成熟 | 支持几乎所有最受欢迎的编程语言:Java,C,C ++,C#,Ruby,Perl,Python,PHP等 | 支持多语言,Java优先 | 支持多语言,Java优先 |
综上:
- Kafka 和 RocketMQ 都支持 10w 级别的高吞吐量。
- Kafka 一开始的目的就是用于日志收集和传输,适合有大量数据产生的互联网业务,特别是大数据领域的实时计算、日志采集等场景,用 Kafka 绝对没错,社区活跃度高,业内标准。
- RocketMQ特别适用于金融互联网领域这类对于可靠性要求很高的场景,比如订单交易等,而且 RocketMQ 是阿里出品的,经历过那么多次淘宝双十一的考验,大品牌,在稳定性值得信赖。但如果阿里不再维护这个技术了,社区有可能突然黄掉的风险。因此如果公司对自己的技术实力有自信,基础架构研发实力较强,推荐用 RocketMQ。
- RabbitMQ 适用于公司对外提供能力,可能会有很多主题接入的中台业务场景,毕竟它是百万级主题数的。它的时效性是毫秒级的,但实际毫秒级和微秒级在感知上没有什么太大的区别,所以它的这一大优点并不太会作为考量标准。同时,它的功能是比较完善的,开源社区活跃度高,能解决开发中遇到的bug,所以万级别数据量业务场景的小公司可以优先选择功能完善的RabbitMQ。它的缺点就是用 Erlang 语言编写,所以很多开发人员很难去看懂源码并进行二次开发和维护,也就是说对于公司来说可能处于不可控的状态。
- ActiveMQ现在很少有人用,没怎么经过大规模吞吐量场景的考验,社区不怎么活跃,官方社区现在对 ActiveMQ 5.x 维护也越来越少,所以不推荐使用。

4 条评论
每一个段落都紧密相连,逻辑清晰,展现了作者高超的写作技巧。
看的我热血沸腾啊www.jiwenlaw.com
想想你的文章写的特别好https://www.ea55.com/
看的我热血沸腾啊https://www.jiwenlaw.com/